Qu’est ce que la tokénization ? Quel est son rôle dans le fonctionnement des LLM ?
La tokénisation est une étape cruciale dans le domaine du traitement automatique du langage naturel (TALN voir ici), en particulier dans le contexte des Large Language Models (LLM). Cette première partie vise à établir un cadre conceptuel solide en explorant le fonctionnement des LLM et en mettant en lumière l'importance de la tokénisation dans ce domaine en constante évolution.
1. Les Grand modèle de langage (LLM) :
Les modèles de langage basés sur les Transformers (voir ici pour plus d'informations sur les Transformers) ont révolutionné le domaine du traitement automatique du langage naturel (NLP) depuis leur introduction par Vaswani et al. en 2017 (disponible ici). Les modèles les plus récents, notamment ceux basés sur GPT (Generative Pre-trained Transformer) tels que GPT-3, ont démontré des performances remarquables dans une variété de tâches linguistiques, allant de la génération de texte à la compréhension de la langue naturelle.
Les Transformers sont principalement constitués de deux composants clés : les encodeurs et les décodeurs. Dans le contexte des modèles de langage, seule la partie encodeur est utilisée. Voici une vue d'ensemble de l'architecture :
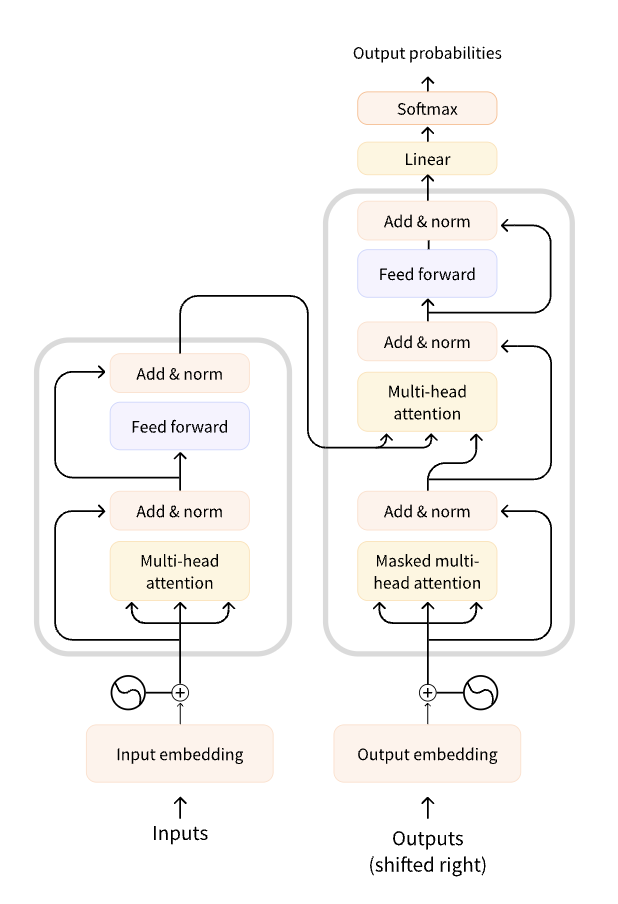
a. Empilement de couches :
Les Transformers comportent plusieurs couches empilées les unes sur les autres. Chaque couche est composée de deux sous-modules principaux : la Multi-Head Self-Attention (auto-attention multi-têtes) et le réseau de feed-forward positionnel.b. Auto-attention multi-têtes :
C'est le mécanisme clé qui permet au modèle de capturer les dépendances à longue portée dans le texte. Il permet à chaque mot dans la séquence d'interagir avec tous les autres mots, donnant une représentation contextuelle pour chaque mot.c. Réseau de feed-forward positionnel :
Après l'auto-attention, une transformation feed-forward est appliquée à chaque position de la séquence. Elle est suivie d'une couche de normalisation et d'une connexion résiduelle.
Une composante fondamentale de l'architecture des LLM est leur processus de tokenization, qui précède souvent le traitement textuel par le modèle. Les tokenizers agissent comme une passerelle essentielle entre le texte brut et le modèle de langage. En segmentant le texte en unités discrètes telles que les mots, les sous-mots ou même les caractères, les tokenizers jouent un rôle crucial dans la normalisation et la structuration du flux de données textuelles. En effet, ces tokenizers établissent une correspondance entre les séquences de mots du langage naturel et les représentations numériques compréhensibles par le modèle. Cette étape de tokenization, souvent sous-estimée, revêt une importance capitale, car elle permet de convertir le texte en une séquence de tokens, facilitant ainsi le traitement et l'analyse par le modèle. De plus, les tokenizers offrent une flexibilité permettant d'adapter la représentation du texte en fonction des exigences spécifiques de la tâche ou des particularités linguistiques, contribuant ainsi à l'efficacité et à la performance globale des modèles de langage. En intégrant harmonieusement les tokenizers dans l'architecture des LLM, ces systèmes peuvent non seulement comprendre et générer du texte avec une précision accrue, mais également s'adapter à une variété de tâches linguistiques avec une agilité remarquable.
2. Qu'est ce que la tokenization ?
D'abord regardons un tokenizer en actions :
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("gpt2")print(tokenizer.encode("Let's understand tokens"))# Output: [5756, 338, 1833, 16326]print(tokenizer.batch_decode(encode("Let's understand tokens"))) # convert token ids to tokens# Output: ['Let', "'s", ' understand', ' tokens']Le modèle de tokénization encode un morceau de texte en une séquence d'identifiants de tokens (ou jetons). Ces identifiants de jetons sont introduits dans un réseau de neuronnes. Le RN possède une couche spéciale au début appelée la couche d'embedding. Correspondant à chaque identifiant de jeton, la couche d'embedding stocke un vecteur d'embedding unique. Étant donné la séquence d'entrée d'identifiants de jetons, la couche d'embedding effectue efficacement une recherche par identifiant de jeton pour produire une séquence de vecteurs d'incorporation. Avant d'aller plus loin, plusieurs questions se posent : Quels sont les tokens (ou jetons) ? Comment décider où diviser un morceau de texte ? Quelles sont les différentes manières de diviser le texte ?
Mais du coup, c'est quoi un token ?
Dans le contexte du traitement automatique du langage naturel (NLP), un token est une unité atomique de texte. La tokenisation ou segmentation du texte est le processus de découpage du texte en unités plus petites et significatives. Idéalement, ces unités devraient être des formes de mots, ou en termes simples, des variations ou dérivations d'un mot. Par exemple, dans le cadre du texte donné, "portefeuille" pourrait être considéré comme un token distinct, même s'il se compose de deux mots ("porter" et "feuille") dans la réalité linguistique.
Plus formellement, dans le cadre de la norme ISO du Cadre d'Annotation Morphologique (MAF), les tokens sont définis comme des séquences contiguës non vides de graphèmes ou de phonèmes dans un document. En termes plus concrets, cela signifie que les tokens sont des séquences de caractères ou de sons qui forment une unité dans le texte. Par exemple, dans le texte en anglais, les tokens sont généralement des mots séparés par des espaces blancs, mais cette convention peut varier selon le script utilisé (par exemple, le japonais n'utilise pas d'espaces blancs pour séparer les mots).
Comme prévu, il y a une bonne dose d'histoire sur l'évolution de la tokenization/segmentation. Initialement, cela se basait uniquement sur des unités typographiques significatives (pour la langue anglaise, il s'agirait de mots et de caractères spéciaux séparés par des espaces blancs), et nous sommes maintenant passés à un niveau plus fin, au niveau des sous-mots. Une excellente étude (voir ici) de Mielke et al. fournit un examen approfondi de la question.
Et comment on fait pour diviser le texte ?
1. Byte-pair encoding (BPE)
L'encodage par paires de bytes (BPE), issu de la théorie de l'information et proposé pour la première fois en 1994, révolutionne les méthodes de tokenization. Initialement, le BPE réalise une tokenization au niveau des caractères du corpus donné. Ensuite, il fusionne les paires de caractères adjacentes les plus fréquentes, créant ainsi de nouveaux tokens de deux caractères de longueur et remplaçant toutes les occurrences de ces paires dans le corpus. Ce processus itératif se poursuit jusqu'à ce que la taille de vocabulaire désirée soit atteinte, passant des caractères individuels à des tokens de longueur variable. Parallèlement, à chaque fusion, le tokenizer enregistre ces transformations sous forme de "règles de fusion" pour une utilisation ultérieure dans la tokenization de texte. Revenant à ses racines théoriques en information, le BPE remplace systématiquement les paires de bytes consécutifs les plus fréquents dans les données par des bytes non utilisés auparavant, ce qui a donné lieu au terme "encodage par paires de bytes". La polyvalence du BPE va au-delà du traitement au niveau des caractères, avec des implémentations telles que celle de GPT-2 qui adopte le BPE au niveau des bytes, où l'encodage est effectué directement sur les bytes bruts plutôt que sur les caractères.
2. Tokenization basé sur les mots
WordPiece est une autre stratégie de tokenization populaire, utilisée dans des modèles tels que BERT, RoBERTa, etc. La tokenization WordPiece est très similaire à celle du BPE, mais elle diffère dans la manière dont les paires sont sélectionnées lors des étapes de fusion. Dans le cas du BPE, les paires sont simplement classées par fréquence, et la paire la plus fréquente est sélectionnée à chaque fois. Avec WordPiece, un score personnalisé est calculé pour chaque paire comme suit : score = (fréq_de_la_paire) / (fréq_du_premier_élément × fréq_du_second_élément) Les paires avec un score plus élevé sont fusionnées à chaque itération. En normalisant la fréquence de la paire par les fréquences individuelles des tokens, seuls les tokens moins fréquents dans le vocabulaire sont fusionnés.
3. Tokenization basé sur les lettres
Les tokenizers basés sur les caractères divisent le texte en unités individuelles de caractères, plutôt qu'en mots. Cette approche présente deux avantages principaux : premièrement, le vocabulaire est beaucoup plus restreint ; deuxièmement, il y a beaucoup moins de tokens hors vocabulaire (inconnus), car chaque mot peut être construit à partir de caractères. Cependant, des questions se posent également concernant les espaces et la ponctuation. Bien que cette approche ne soit pas parfaite, puisque la représentation est basée sur les caractères plutôt que sur les mots, on pourrait soutenir qu'elle est intuitivement moins significative : chaque caractère ne possède pas autant de sens individuellement que les mots. Toutefois, cela varie également selon la langue ; par exemple, en chinois, chaque caractère contient plus d'informations qu'un caractère dans une langue latine. Un autre aspect à considérer est que cela conduit à un nombre très élevé de tokens à traiter pour notre modèle : alors qu'un mot ne serait qu'un seul token avec un tokenizer basé sur les mots, il peut facilement se transformer en 10 tokens ou plus lorsqu'il est converti en caractères.
4. Tokenization basé sur les sous-mots (subword tokenization)
Les algorithmes de tokenization par sous-mots reposent sur le principe selon lequel les mots fréquemment utilisés ne doivent pas être divisés en sous-mots plus petits, mais que les mots rares doivent être décomposés en sous-mots significatifs. Par exemple, "ennuyeusement" pourrait être considéré comme un mot rare et pourrait être décomposé en "ennuyant" et "ment". Ces deux sous-mots ont plus de chances d'apparaître plus fréquemment de manière autonome, tout en conservant le sens de "ennuyeusement" grâce à la signification composite de "ennuyant" et "ment". Un exemple montre comment un algorithme de tokenization par sous-mots pourrait diviser la séquence "Faisons de la tokenization !" Ces sous-mots offrent une grande richesse sémantique : par exemple, dans l'exemple ci-dessus, "tokenization" a été divisé en "token" et "ization", deux tokens qui ont un sens sémantique tout en étant efficaces en termes d'espace (seuls deux tokens sont nécessaires pour représenter un long mot). Cela nous permet d'obtenir une couverture relativement bonne avec de petits vocabulaires et quasiment aucun token inconnu. Cette approche est particulièrement utile dans les langues agglutinatives telles que le turc, où il est possible de former (presque) arbitrairement de longs mots complexes en enchaînant des sous-mots.
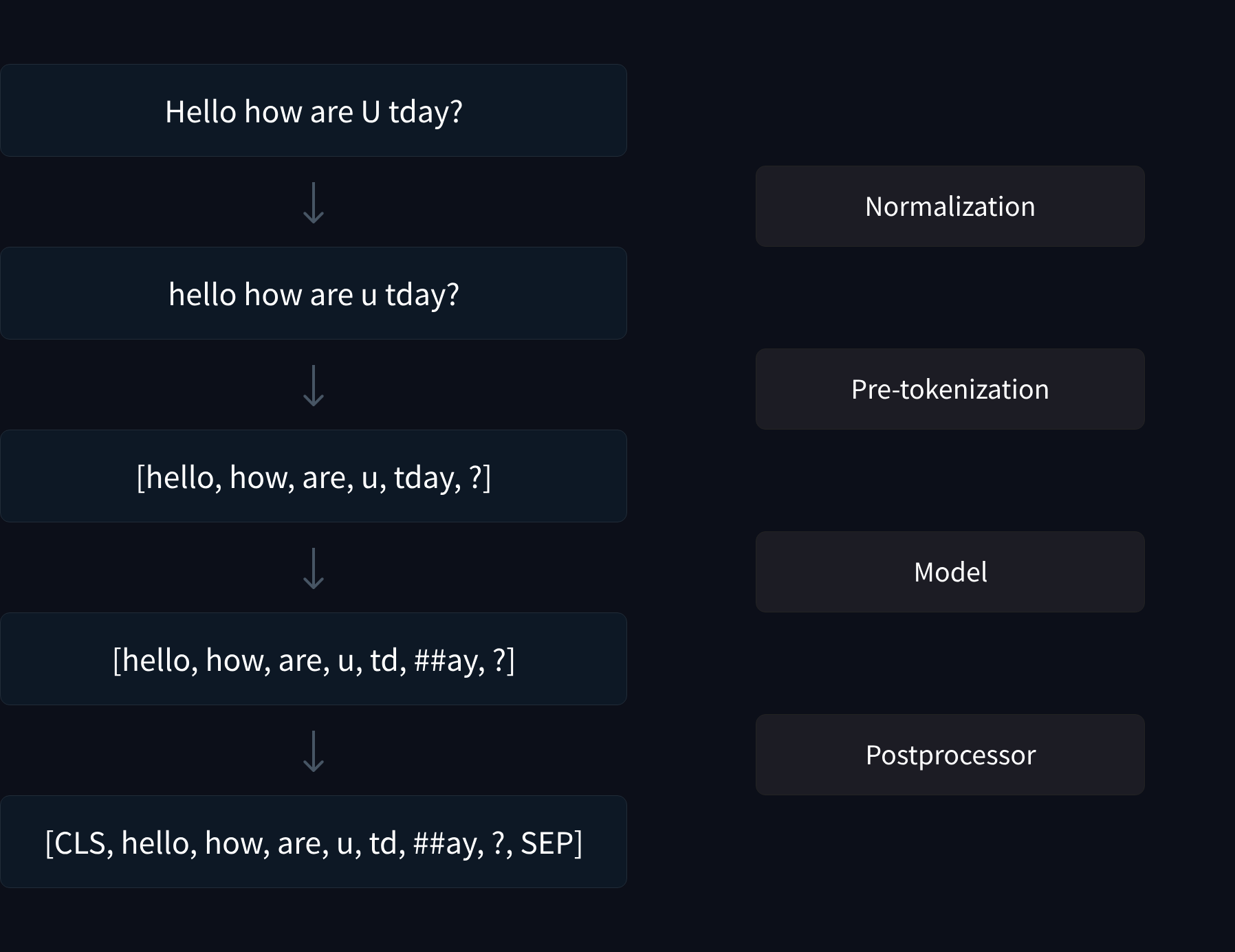
La pipeline de tokenization :
Maintenant regardons les différentes étapes de tokénization sans forcèment définir chacune d'entre elles :
- 1. Normalisation : Convertir le texte en minuscules (lowercasing) et supprimer les accents et d'autres caractères spéciaux, selon les besoins.
- 2. Pré-tokenisation : Optionnellement, diviser le texte en mots en se basant sur les espaces blancs (si applicable pour cette langue).
- 3. Modélisation : Utiliser l'algorithme de tokenization pour convertir le texte ou la liste de mots en une liste de tokens.
- 4. Post-traitement : Ajouter des tokens spéciaux tels que les séparateurs de séquence, le début et la fin de la séquence, etc.
Une excellente visualisation issue du cours "Tokenizers" de hugging face (disponible ici) permet de mieux comprendre chaque étape :
Tokenizer... Ce n'est pas aussi facile qu'il n'y paraît.
Dans cette partie nous allons traiter des différents challenge auxquels l'on fait face lorsque l'on tokénizer. En effet, la tokenization peut être complexe et présenter des défis majeurs, notamment lorsqu'il s'agit de traiter des nombres et des opérations mathématiques, de tokeniser différentes langues non latines, ou encore d'adapter la tokenization pour des modèles multi-langues.
1. Tokenizer des nombres (et opération arithmétiques).
La tokenisation des nombres et des opérations arithmétiques pose un défi particulier en raison des différentes façons de représenter et de manipuler les nombres dans un texte. Bien que le système numérique décimal offre une approche structurée pour représenter les nombres à l'aide de symboles uniques, tels que les chiffres de 0 à 9 et le point décimal, parvenir à une stratégie de tokenisation cohérente basée sur ce système est loin d'être simple en pratique.
Prenons l'exemple du modèle T5, où le nombre "410" est tokenisé comme une seule unité, mais les nombres comme "411" ou "490" sont segmentés en plusieurs jetons. Cette incohérence découle de la méthodologie utilisée par les algorithmes de tokenisation, tels que le codage par paires de bytes (BPE), pendant l'entraînement. Le BPE vise à comprimer efficacement le corpus d'entraînement en identifiant des motifs récurrents, ce qui entraîne des schémas de tokenisation variables pour différents nombres en fonction de leur fréquence d'occurrence dans les données. Par conséquent, les nombres ronds comme "400" peuvent être tokenisés comme une seule unité en raison de leur fréquence plus élevée, tandis que des séquences plus arbitraires comme "4134" peuvent être divisées en plusieurs jetons.Bien que cette approche de tokenisation non uniforme puisse aider à la compression, elle pose des défis pour les tâches ultérieures, notamment dans les opérations arithmétiques. Les embeddings pour les nombres proches les uns des autres sur la ligne des nombres peuvent différer considérablement en raison des divisions arbitraires pendant la tokenisation. Pour résoudre ce problème, les modèles récents ont adopté des stratégies pour garantir une plus grande uniformité dans la tokenisation.Par exemple, le modèle Llama tokenise tous les nombres comme des chiffres individuels, quel que soit leur magnitude ("410" et "411" sont tous deux segmentés en trois jetons). De même, Falcon tokenise les nombres de 0 à 999 comme des jetons uniques, avec seulement quelques exceptions comme "957" nécessitant plusieurs jetons. Même des modèles avancés comme GPT-4 intègrent des pratiques de tokenisation uniformes, où les entiers jusqu'à 999 sont représentés par des jetons uniques, tandis que les nombres plus grands sont décomposés en fonction de ces unités plus petites.La recherche d'une uniformité dans la tokenisation est motivée par le désir d'équiper les modèles de langage d'une compréhension fonctionnelle des entiers. Bien que les modèles de langage ne reçoivent pas directement des entiers en entrée, ils doivent avoir la capacité d'effectuer efficacement des opérations arithmétiques. Ces opérations comprennent les fonctions arithmétiques de base telles que l'addition, la soustraction, la multiplication et la division, ainsi que les opérations d'ordre telles que l'égalité, le plus grand que et le plus petit que. En garantissant une stratégie de tokenisation cohérente, les modèles de langage peuvent mieux apprendre et généraliser ces opérations fondamentales, améliorant ainsi leurs performances globales dans les tâches arithmétiques.En conclusion, bien que la tokenisation des nombres et des opérations arithmétiques pose des défis dans le TALN, les avancées récentes dans les techniques de tokenisation visent à atteindre une plus grande uniformité pour faciliter le traitement précis et efficace des informations numériques dans les données textuelles. En adoptant des stratégies qui privilégient la compréhension fonctionnelle et la cohérence, les modèles de langage peuvent naviguer efficacement dans les tâches arithmétiques et contribuer à l'avancement de la linguistique computationnelle.2. Tokenizer des langues non-latines.
La capacité à traiter du texte dans plusieurs langues est un élément essentiel de nombreuses applications de TALN. Par exemple, le modèle de transcription de la parole en texte de Whisper, développé par OpenAI (qui est un simple modèle de transformer encodeur-décodeur), peut traiter sans problème la parole en anglais et en chinois. Bien sûr, il ne s'agit pas simplement d'une application de texte d'entrée -> texte de sortie, mais le point crucial est que la tokenization dans d'autres langues, notamment les langues à ressources limitées, pose son propre ensemble de défis.
Le premier et probablement le plus grand défi est le manque de données d'entraînement de haute qualité pour de nombreuses langues. Des langues comme l'anglais, le chinois, le russe, etc., disposent de beaucoup plus de contenu disponible sur Internet que, par exemple, le kannada et le swahili. De plus, il existe des différences fondamentales entre les langues, telles que l'absence d'un séparateur typographique (par exemple, un espace blanc en anglais) dans certaines langues comme le chinois et le japonais. Certaines langues présentent également des règles de script complexes, en particulier en ce qui concerne la manière dont les consonnes et les voyelles se combinent. En kannada, par exemple, le mot pour "langue" est ಭಾಷೆ. ಭಾ est une combinaison de la consonne 'ಭ' et du signe de voyelle 'ಾ'. On souhaite avoir un tokenizer qui reconnaît ಭಾ comme une unité significative et un jeton distinct, et ne le décompose pas davantage en consonne et en signes de voyelle.3. Tokenizer pour des modèles multilingues.
La complexité et l'importance de la tokenization pour les modèles multilingues résident dans la nécessité de traiter efficacement une grande variété de langues, chacune ayant ses propres caractéristiques linguistiques et ses particularités. Lors de la construction d'un système multilingue, une question clé est de savoir comment choisir et adapter les tokenizers pour chaque langue afin d'optimiser les performances du modèle.
Par exemple, dans le cas d'un modèle de traduction automatique, une approche consiste à apprendre un tokenizer spécifique pour chaque langue. Imaginons un modèle encodeur-décodeur transformer entraîné à traduire de l'anglais vers le français. Dans ce cas, le texte d'entrée serait tokenisé et numérisé en fonction, par exemple, d'un tokenizer BPE entraîné sur du texte anglais. Les embeddings correspondants à chaque jeton seraient récupérés, puis passés à travers le transformer. À la sortie du décodeur, on sélectionne la classe/ID la plus probable pour chaque position dans la séquence de sortie, les IDs étant basés sur le vocabulaire d'un tokenizer BPE entraîné en français. Lorsque les jetons décodés sont réinjectés dans le décodeur, une couche d'embedding de sortie différente est utilisée pour mapper les jetons décodés aux embeddings qui sont transmis au décodeur.Cependant, la construction de modèles multilingues capables de traduire entre un grand nombre de langues (et pas seulement dans une seule direction) pose des défis supplémentaires. Une approche simple consisterait à mélanger toutes les données disponibles pour toutes les langues. Cependant, il existe toujours des disparités significatives dans la quantité de données disponibles pour chaque langue, ce qui se traduit par un déséquilibre dans le nombre de jetons dédiés à chaque langue dans le vocabulaire. Cette disparité peut conduire à une tokenization proche du niveau des caractères pour les langues avec très peu de données, ce qui peut compromettre les performances du modèle.En outre, les règles complexes des scripts linguistiques peuvent également avoir un impact sur les performances du modèle. Par exemple, la combinaison de consonnes et de voyelles dans des langues comme le kannada ou le swahili peut nécessiter une tokenization spécifique pour capturer correctement le sens des mots.Ainsi, la conception de modèles multilingues efficaces nécessite une attention particulière à la tokenization afin de garantir une représentation adéquate des différentes langues et d'optimiser les performances du modèle sur une large gamme de tâches de traitement du langage naturel.Des solutions existent !
our relever les défis de la tokenization dans les modèles multilingues, plusieurs approches ont été envisagées. Une méthode consiste à adapter les tokenizers existants aux spécificités de chaque langue. Par exemple, pour le chinois et le japonais, qui ne séparent pas les mots par des espaces, des tokenizers ont été développés pour segmenter correctement le texte en unités significatives. De même, des adaptations sont nécessaires pour les langues avec des règles de script complexes, telles que le kannada, où les consonnes et les voyelles peuvent se combiner de manière particulière. Une autre approche implique l'utilisation de techniques de prétraitement pour normaliser les textes, telles que la suppression des accents ou la standardisation des orthographes. Par exemple, pour les langues avec des caractères accentués comme le français ou l'espagnol, une étape de prétraitement peut être nécessaire pour convertir les caractères accentués en leurs équivalents non accentués. Enfin, des efforts sont déployés pour développer des tokenizers spécifiques pour les langues moins représentées. Par exemple, dans le cadre de projets de TALN pour les langues autochtones, des tokenizers sont développés pour capturer les particularités linguistiques de ces langues et assurer une représentation adéquate dans les modèles multilingues.
Une initiative importante dans ce domaine est "No Language Left Behind" (NL2B), qui vise à développer des technologies de TALN inclusives en garantissant une représentation équitable de toutes les langues, y compris celles à ressources limitées. NL2B encourage la collaboration entre chercheurs et communautés linguistiques pour collecter des données, développer des modèles et des outils adaptés à chaque langue, afin de favoriser l'accès aux technologies de TALN dans le monde entier.Crédits
Je tiens à exprimer ma reconnaissance envers Sumanth R Hegde, principal contributeur du dépôt GitHub suivant pour son travail inspirant sur la tokenization :
Repo GitHub : tokenizationJe suis également reconnaissant envers les cours de Hugging Face (disponibles ici) sur le traitement automatique du langage naturel (NLP), qui ont fourni une base de connaissances précieuse pour la rédaction de ce rapport.Enfin, je souhaite adresser mes sincères remerciements à mon tuteur Alexandre Chapin, doctorant à l'Ecole Centrale de Lyon pour son soutien tout au long de ce projet, ainsi qu'à Bilel Omrani Lead Data Scientist à Illuin Technology pour ses précieux conseils et assistance.